
Research
My research focuses on developing trustworthy and explainable multimodal artificial intelligence (AI) systems for healthcare. I apply state-of-the-art AI technologies to provide clinical decision support and optimize clinical workflows. Below you will find a sample of the projects I work(ed) on.
WATCH-SS (Warning Assessment and Alerting Tool for Cognitive Health from Spontaneous Speech)
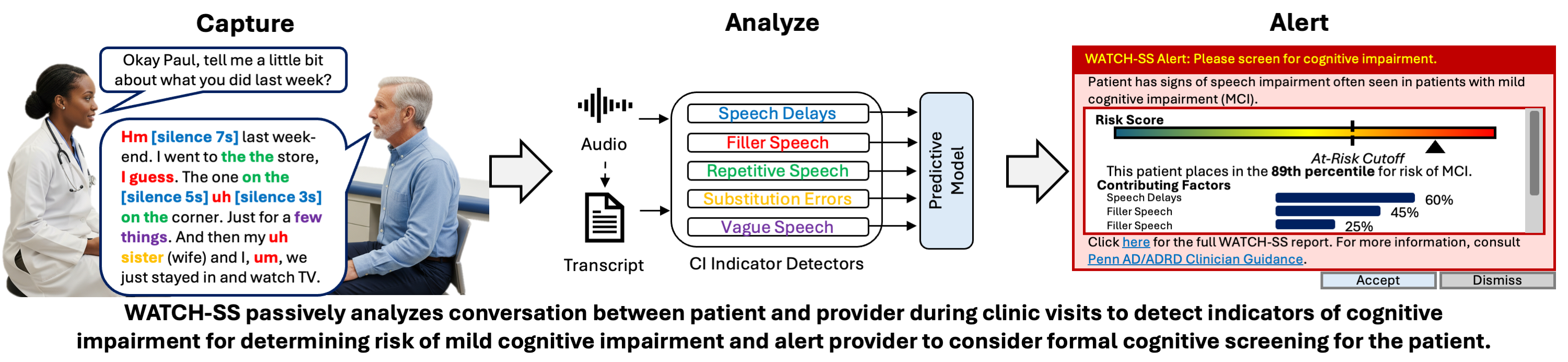
Over 50% of people living with Alzheimer’s disease (AD) are undiagnosed. Many people who have emerging concerns about their cognitive health first consult their primary care physician (PCP), but very few actually receive a diagnosis for cognitive decline due to factors like PCPs’ time constraints, competing priorities, lack of expertise or comfort with AD diagnosis. Thus we are developing WATCH-SS, a screening tool for primary care which passively analyzes a patient’s speech during a clinic visit to assess risk of cognitive impairment (CI). To do this, WATCH-SS runs a set of detectors for five acoustic and linguistic signs of CI and these detections are fed through a predictive model to predict CI. The detectors are a mixture of natural language processing (NLP) -based algorithms and large-language models (LLMs). Our evaluation shows that WATCH-SS achieves strong predictive performance (AUC 0.95 for test and 0.80 for train on DementiaBank data), and its design allows us to effectively explain and verify our risk prediction.
Evaluating Robustness of Medical AI Systems with Naturally Adversarial Datasets
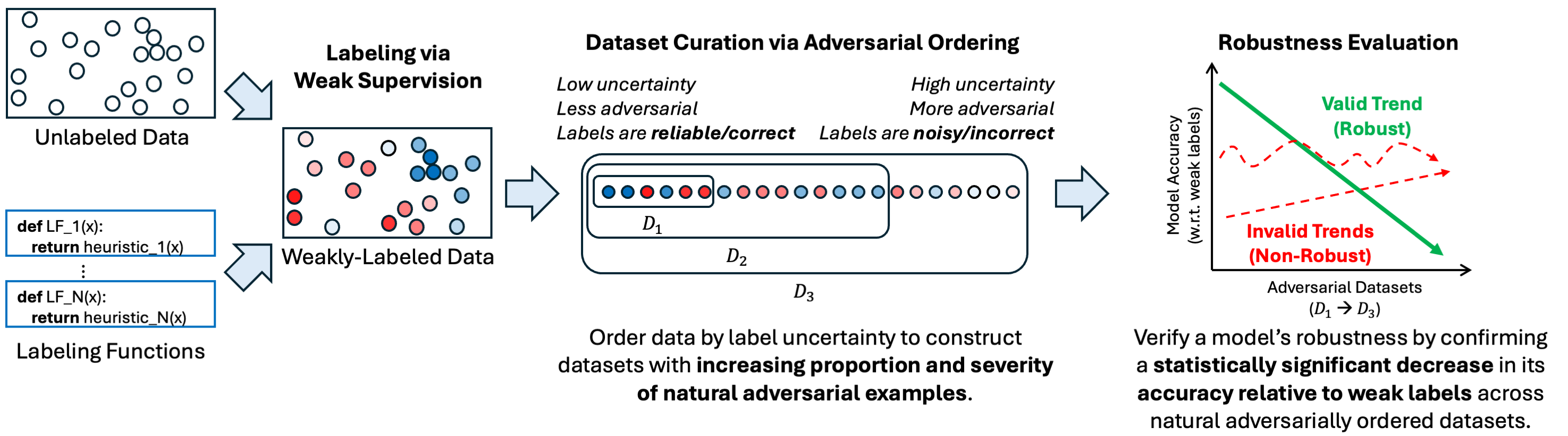
To ensure robustness of medical AI systems, we must move beyond unrealistic synthetic perturbations and evaluate against naturally occurring adversarial examples that reflect true healthcare challenges and effectively deceive models. To address this, we developed a weakly-supervised framework that curates naturally adversarial datasets for evaluating robustness using existing real-world unlabeled data. Our method first generates probabilistic labels via weak supervision, then orders the examples based on label uncertainty to generate a sequence of datasets that are progressively more adversarial. We can then validate model robustness by confirming a statistically significant decrease in agreement between model predictions and weak labels across the datasets. This trend reflects the expectation that a robust model maintains accuracy on both expected and unexpected inputs, effectively diverging from weak labels as they become unreliable on the unexpected inputs.
Evaluating Physiologic Monitoring Alarm Suppression Systems with High-Confidence Data Programming

Deploying alarm suppression algorithms requires rigorous validation, yet obtaining the expert-labeled datasets needed to test them is often prohibitively expensive. We introduce a High-Confidence Data Programming framework that enables researchers to evaluate classifiers directly on massive unlabeled datasets. By combining clinical heuristics into probabilistic labels and filtering for only the highest-confidence examples, our method generates a ‘proxy ground truth.’ This allows us to derive statistical confidence bounds for a model’s sensitivity and specificity, providing a reliable performance estimate without the need for manual annotation.
Automating Weak Label Generation for Data Programming with Clinicians in the Loop

Deep learning in healthcare is often stalled by the data bottleneck—the prohibitive cost of obtaining expert-annotated large datasets. We propose a clinician-in-the-loop framework that automates weak label generation by identifying the most representative data “memories” in the data using the CLARANS clustering algorithm with domain-specific distance metrics—such as Dynamic Time Warping (DTW) for physiological signals and Kullback-Leibler (KL) divergence of OpenAI’s CLIP embeddings for medical images. A clinician then labels these memories, enabling our framework to propagate expert annotations from this small handful of examples to the remaining unlabeled data. This approach significantly reduces manual labeling effort while achieving accuracy comparable to existing weak supervision baselines.